Qwen 3.6 vs gpt-oss:120b on M3 Max: I Ran a Harder Test, the 8× Speed Gap Surprised Me
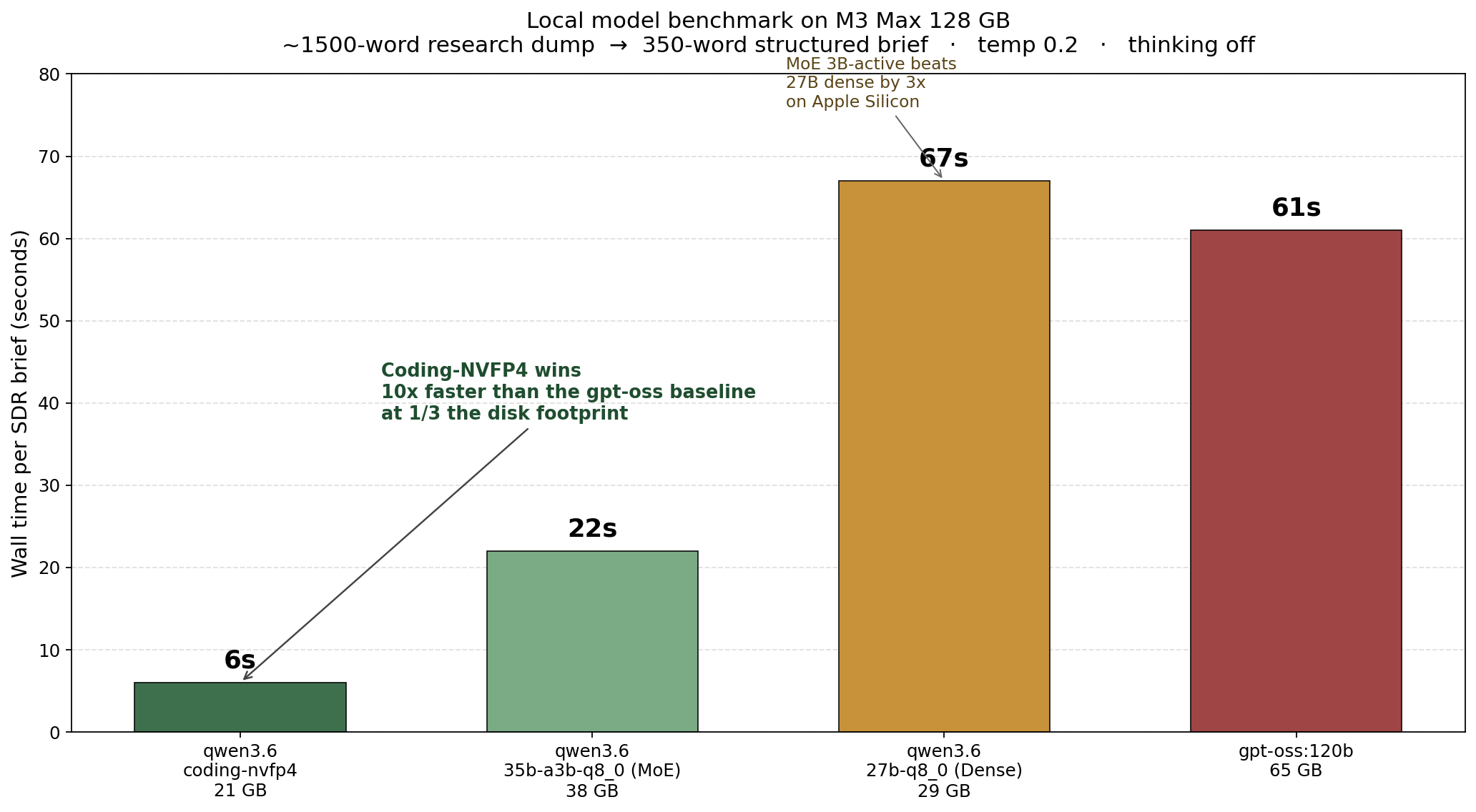
I published a Qwen 3.6 vs gpt-oss migration story, then ran an un-gameable eval against both on the same M3 Max. The receipts changed the speed narrative — gpt-oss:120b ran 8 to 11 times faster than qwen3.6:27b at parity reasoning quality. Here is the methodology and the data.
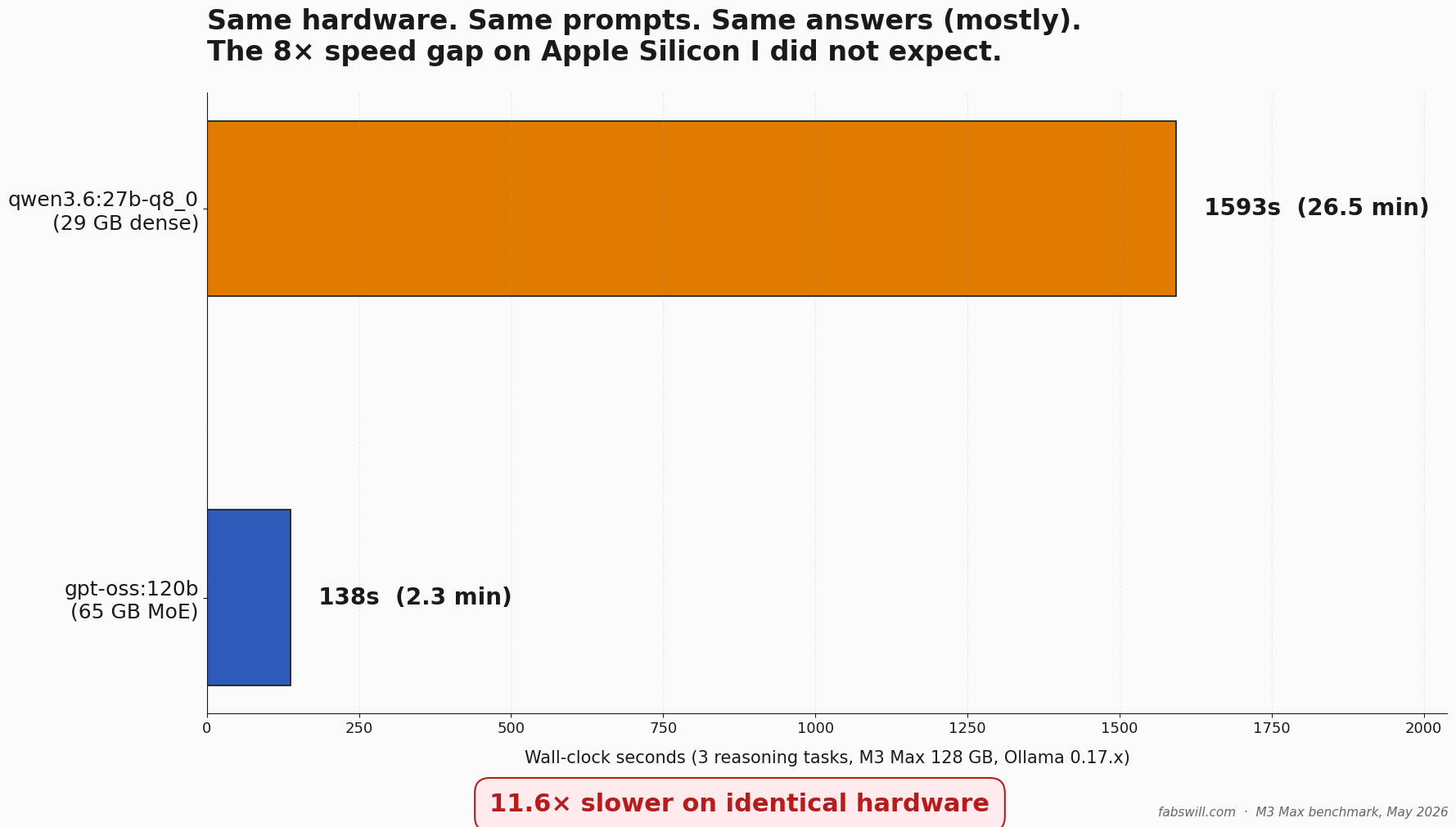
I published a post last week about replacing gpt-oss:120b with Qwen 3.6 on my MacBook Pro M3 Max. The numbers in that post were real, but one set of tests was structurally gameable — 38 of 40 baseline images were the same class, so an “always-say-A” stub also scored 95 percent. I went back, designed three un-gameable reasoning tasks, and ran them against both local models on identical hardware. gpt-oss:120b finished the three tasks in 137 seconds. qwen3.6:27b-q8_0 took 1593 seconds —…