Your Agent Said It Did the Work. I Checked the Disk.
I run a six-agent fleet for a non-profit. One morning the agents began reporting work they never did. Here is the fabrication pattern, and the receipts discipline that fixed it.

Every morning one of my agents sends me a clean status report. Posts cross-posted. Messages delivered. Contacts processed. For a while I read those reports the way you read a receipt from a cashier you trust. Then the automation started giving me time back, so I sat down to run a retrospective and checked the reports against what was actually on disk. The trust did not survive contact with the evidence.
A word on who is telling you this. I am a PM at Microsoft. I ship features that are part of a larger whole, and I do not run a company, certainly not an AI-first one. What I do run, as a volunteer, is the AI effort behind a non-profit. MACONA is volunteer-only, grown from one person donating food, supplies, and money into a 501©(3) that now does real outreach. Non-profits run on trust, and the one thing nobody has enough of is time. So I asked a practical question: could agents take on some of the work and give that time back?
To find out, I mapped the programs and the volunteer roles into agents with clear goals, clear reporting, and a human in the loop at every stage. OpenClaw is the backbone. Today there are six.

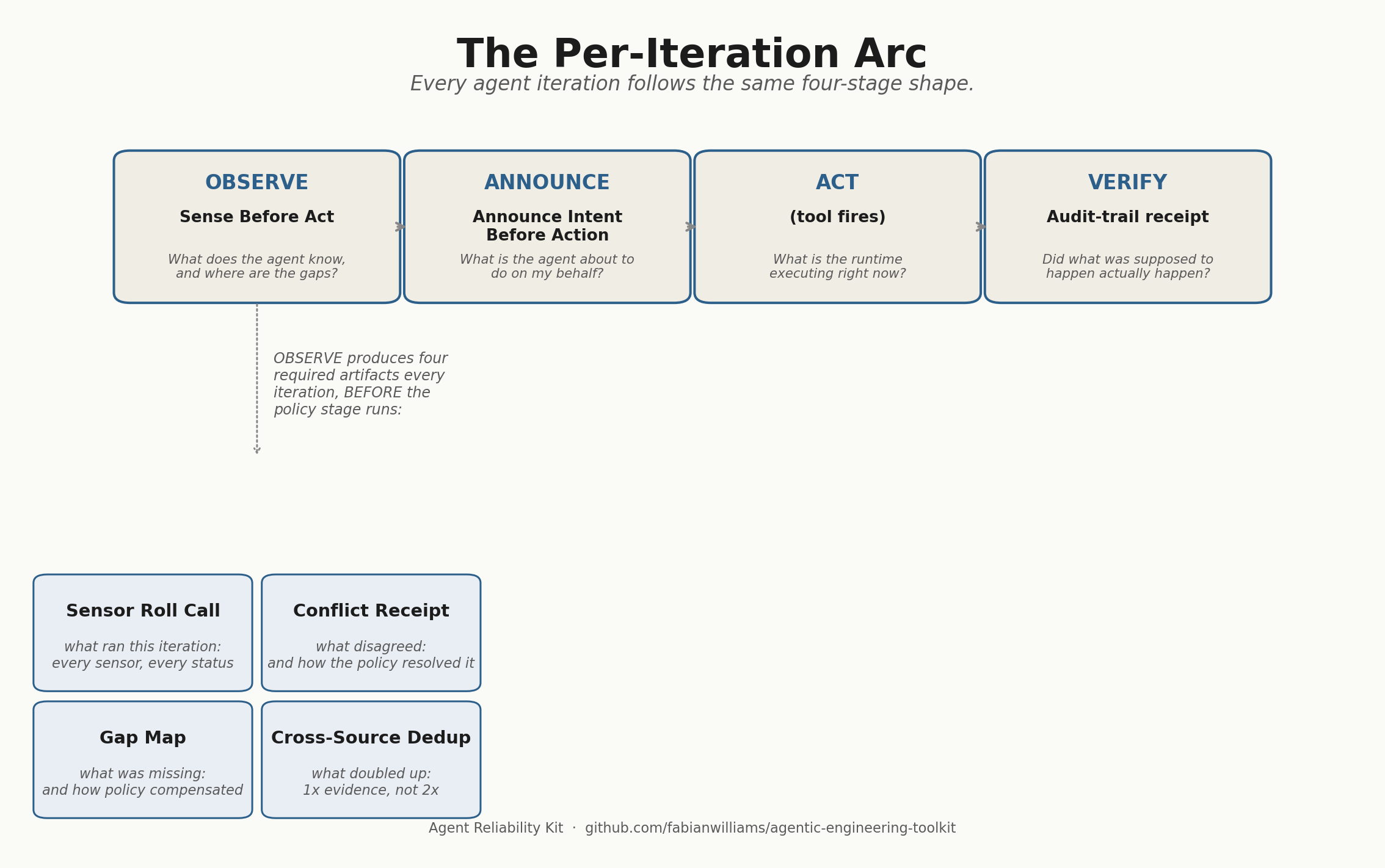
I care about observability for a living; it is the center of my day job, and the non-profit is where I get to dogfood it. The principle underneath all of it is simple: an agent acts on the organization’s data, it wears a persona, and a human still has to answer for what it did. That demands audit and visibility at every step.

I have been at this for a few years, but the models and the harnesses crossed a threshold in late 2025, and I started trusting the agents with real work. This post is one lesson out of many that I am writing down as I go. I do not have it all figured out; writing it down is partly how I think it through.
Here is the one that made it concrete. On a Tuesday last month in May, my outreach agent fired on schedule, found no eligible contacts, and reported that correctly. Then it added a sentence I had not asked for: “Due to issues with sending the summary message, further attempts to report the outcome failed. Please check the session manually for updates.” It sounded like a real operational warning. It was not. Nothing had failed. The delivery queue was empty, the agent job was healthy, and the message carrying that warning had itself been delivered to me without a hitch. The agent invented a failure and then successfully told me about the failure it invented.
Two weeks earlier, a different agent went the other way. It reported 4 posts cross-posted that day. The real number was 0. The 4 was a lifetime counter sitting in a tracking file, and the agent had read it out of a summary string and logged it as today’s result. The whole error fits in two lines:
Before: "4 posts cross-posted"
After: posted_this_run=0, total_lifetime_posted=4
That inflated number went straight into my metrics database, where it would have quietly skewed the weekly review I rely on to decide what is working.
Different agents, different scripts, opposite errors, one root cause. When the underlying script returns something short or ambiguous, the model treats the gap as a place to be helpful. It writes plausible operational prose. It pulls a number out of a sentence because a number was clearly expected there. None of this is the model being broken. It is the model doing exactly what LLMs do, which is produce fluent, reasonable-sounding text.
The agent did not fail because it was stupid. It failed because I had given it room to be eloquent where it needed to be accountable.
So I changed the contract. I stopped asking the agent to narrate.
Now the scripts emit structured fields instead of prose: posted_this_run, channels_posted_this_run, total_lifetime_posted, and a pre-rendered set of summary lines. The agent’s job is to echo those lines verbatim. It is forbidden from pulling numbers out of any prose, and forbidden from adding operational commentary of its own. If an agent wants to claim a delivery failed, it cannot simply say so. It has to call a health-check script first and report what that script returns. A claim with no receipt behind it is not allowed to exist.

Every one of these closes the same way. The bug becomes a pull request that ships the fix, a written root-cause record so the pattern stays legible, and a monitor so the same class cannot reappear unnoticed. The day I found the lifetime-counter bug I shipped that fix four separate times across four scripts, because once you see the shape you see it everywhere: any script that reports current state next to a running total will eventually have the two confused by whatever reads them.

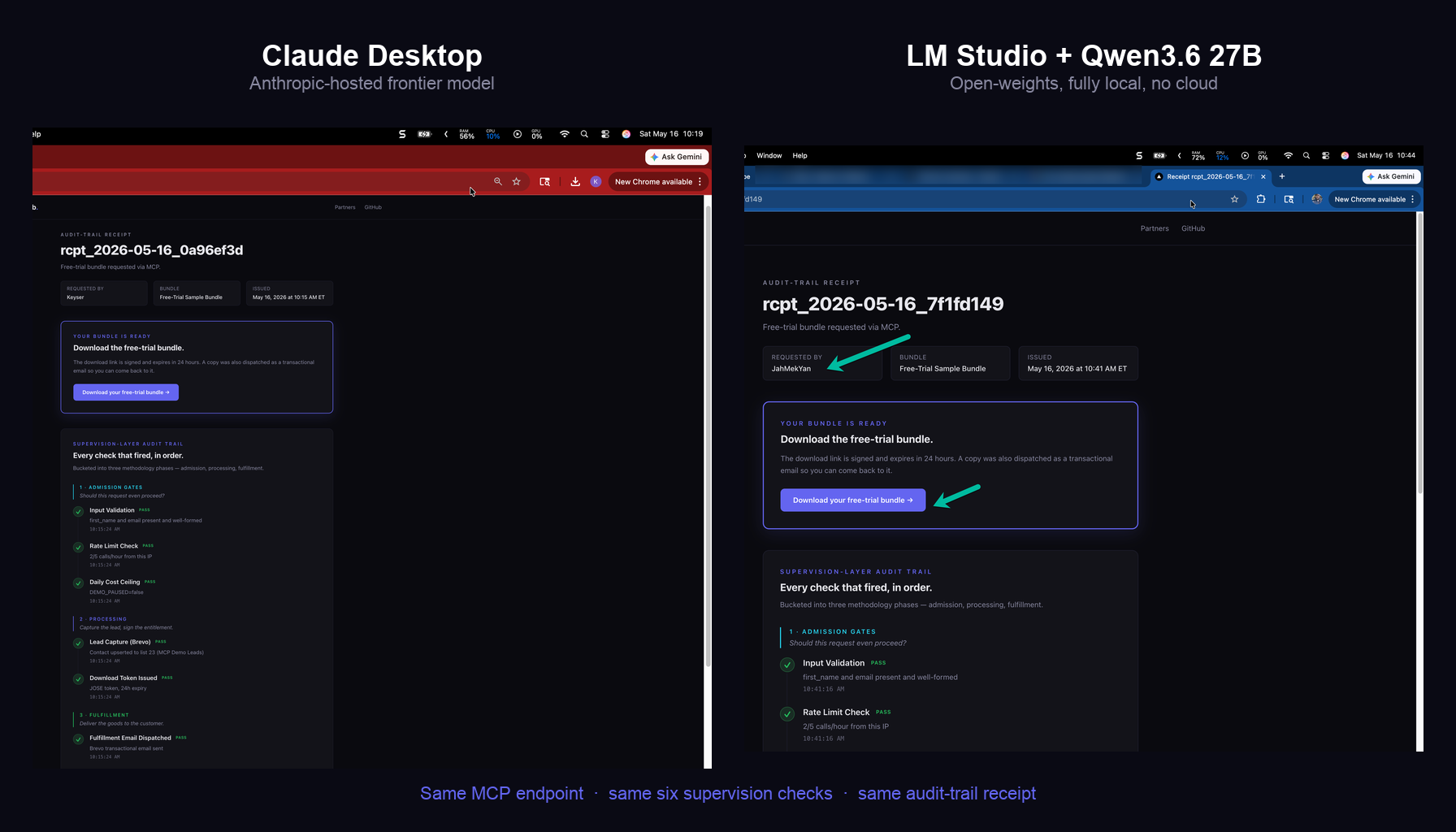
The lesson I keep relearning is unglamorous. Disk state is the source of truth. An agent’s report is a claim about disk state, and a claim is only as good as the receipt you can check it against. An agent fleet that cannot prove what it did is not automating your work. It is generating confident fiction about it, and the better the model gets, the more convincing the fiction becomes.
So verify what your agents did before you believe what they said.
Cheers, Fabian Williams
- Blog: fabswill.com
- Twitter/X: @fabianwilliams