Sense Before Act: Four Artifacts Every Agent Iteration Must Produce Before It Decides
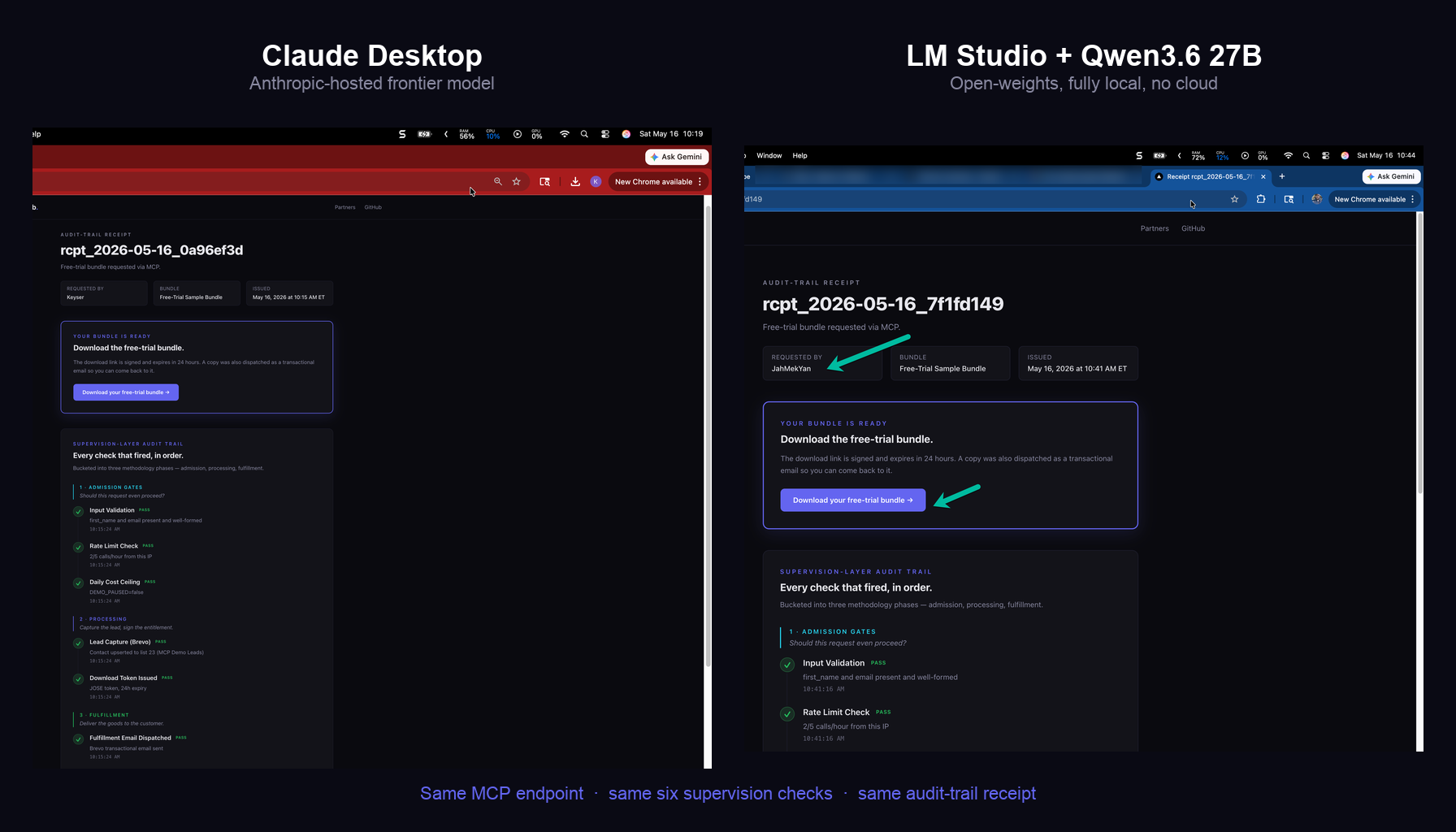
The matched observation-side discipline to announce-intent-before-action. Four small artifacts (Sensor Roll Call, Conflict Receipt, Gap Map, Cross-Source Dedup) the agent must emit before any decision. Currently running on a real fleet at MACONA; the receipts are public.

By the end of this post you will know what every iteration of every production agent must produce BEFORE it decides anything: four small artifacts that catch the failures sharper prompts cannot prevent. You will know why “tell the model to be careful” never worked as a defense, and why the only durable fix is structural. And you will know what the discipline looks like in code, because we have been running it at MACONA for months and the receipts are public.
The discipline most agent vendors do not ship
There is a failure mode in production agent fleets that no model upgrade fixes and no prompt instruction prevents. It looks like this:
- An agent reads from five sources of state.
- One source returned an empty list this iteration. The other four returned data.
- The agent writes a confident summary that quietly assumes the empty source was empty for a reason, not because the API call timed out.
- The summary looks correct. The supervisor approves it. The decision downstream cascades from a fact the agent never actually verified.
Multiply that pattern across multi-hour runs, eight parallel documents, dozens of cron iterations a day, and you do not have a model problem. You have a working-environment problem. The agent is doing exactly what it was asked to do. The error is structural; it was baked into the iteration before the policy stage ran.
The fix is older than software. It is the scientific method, applied at agent runtime. Observe the system. Name what disagrees. Name what is missing. Deduplicate evidence. THEN form a hypothesis. THEN test it. THEN update the model of the world. Centuries-old discipline. The only thing new is that agents now run unsupervised across multiple sources of state, and the operator cannot read four notebooks before every iteration of a loop that fires hourly.
So the runtime has to keep the notebooks instead. Four small artifacts, emitted every iteration, BEFORE the agent decides anything. That is the discipline. We call it Sense Before Act, and it is the matched pair to a discipline we shipped last week called Announce Intent Before Action. Together the two close the agent’s per-iteration arc: observe, announce, act, verify.
The four artifacts
Each agent iteration following this discipline must produce all four. None is optional. A sensor that returned nothing is still recorded as “checked, returned nothing.” A sensor that errored is still recorded as “checked, errored, reason.” Silent omission of any sensor is forbidden, because silent omission is exactly the failure mode the discipline exists to prevent.
1. Sensor Roll Call
Every sensor that was called this iteration, with timestamp, return shape, and outcome. Not just the ones that succeeded; ALL of them.
{
"sensor_roll_call": {
"iter_id": "iter_20260522_125600",
"started_at": "2026-05-22T12:56:00Z",
"sensors": [
{ "name": "telegram", "status": "ok", "items": 0, "duration_ms": 412 },
{ "name": "brevo_smtp", "status": "ok", "items": 17, "duration_ms": 980 },
{ "name": "daily_summary", "status": "not_found", "items": 0, "duration_ms": 14 },
{ "name": "rca_files", "status": "ok", "items": 2, "duration_ms": 31 },
{ "name": "openclaw_jobs", "status": "not_found", "items": 0, "duration_ms": 8 }
]
}
}
Every sensor the constitution declares as enabled MUST appear. Even if its status is not_found or errored. The quality gate stage rejects iterations that quietly drop a sensor.
2. Conflict Receipt
Every place where two sensors (or two records from one sensor) disagreed about the same underlying fact, and the policy stage’s resolution.
{
"conflict_receipt": {
"iter_id": "iter_20260522_125600",
"conflicts": [
{
"fact": "last_send_to_dr_uzo",
"sensor_a": { "name": "brevo_smtp", "value": "2026-05-20T14:11:00Z" },
"sensor_b": { "name": "rca_files", "value": "2026-05-19" },
"resolution": "trust_sensor_a",
"reason": "brevo_smtp has wall-clock timestamps; rca_files uses calendar date and lags up to 24h"
}
]
}
}
When there are no conflicts, the receipt still emits with "conflicts": []. The discipline is “we looked for conflicts and here is what we found,” not “we did not see any conflicts so we wrote nothing.” The empty receipt is the proof we looked.
3. Gap Map
Every not_found, every sensor error, every piece of state the agent decided not to check. The gap map is the agent’s confession of what it does NOT know this iteration.
{
"gap_map": {
"iter_id": "iter_20260522_125600",
"gaps": [
{
"field": "daily_summary",
"kind": "not_found",
"what_we_would_know_if_present": "cron-reasoned end-of-day rollup for prior day",
"policy_compensation": "downgrade confidence on any inference that depends on prior-day rollup"
},
{
"field": "openclaw_jobs",
"kind": "not_found",
"what_we_would_know_if_present": "current scheduled job registry snapshot",
"policy_compensation": "skip any reasoning about jobs.json drift this iteration"
}
]
}
}
Every gap names what would be known if the gap were filled AND how the policy stage compensates. A gap without a named compensation is a discipline violation, because then the policy is guessing in the dark.
4. Cross-Source Dedup
Every fact that appeared in two or more sensor outputs, with the dedup decision. Two sensors observing the same event is one piece of evidence, not two.
{
"cross_source_dedup": {
"iter_id": "iter_20260522_125600",
"dedup_decisions": [
{
"fact": "telegram_alert_brevo_bounce_2026_05_22_0712",
"seen_in": ["telegram", "brevo_smtp"],
"treated_as": "1x_evidence",
"primary_source": "brevo_smtp",
"reason": "brevo_smtp is the originator; telegram is a forwarded copy"
}
]
}
}
When the same underlying event appears in N sensors, the policy stage MUST receive it as one event with a seen_in list, never as N independent events. Failure to dedup inflates evidence weight on whatever the duplicated source happens to repeat most often. That is how doubled telemetry quietly biases agent behavior.
A sensor that errored is still a sensor that ran. The discipline is “we looked,” not “we found.” Empty receipts are the proof we looked.
Why exactly these four
Each artifact answers a specific failure question that long-horizon agent work tends to fail on:
| Artifact | Failure it prevents | What happens without it |
|---|---|---|
| Sensor Roll Call | Silent sensor failure | Agent acts as if a sensor returned clean data when in fact it errored |
| Conflict Receipt | Smoothing over disagreement | Agent picks one source arbitrarily, hides that the other source disagreed |
| Gap Map | Inventing around missing data | Agent confabulates plausible content to fill a hole |
| Cross-Source Dedup | Double-counting evidence | Policy stage over-weights whatever happens to be duplicated |
Three artifacts catch most cases. Four catch the realistic span. Fewer than four leaves a known hole; more than four adds ceremony without adding coverage.
What this looks like running in production
The reference implementation is ADOTOB Loop, currently running on a Microsoft Surface in suburban Maryland. The Surface belongs to the MACONA OpenClaw fleet, a small nonprofit-side agent cluster that has been in production for months. ADOTOB Loop is the stage-5 learning loop sitting on top of it; the Self-Improving Fleet Loop discipline names what each stage does, and Sense Before Act lives at stage 1.
The loop fires hourly as a Windows Scheduled Task running as SYSTEM, every iteration at minute :56. Since the install on the evening of 2026-05-21, the loop has completed roughly twenty clean iterations in --dry mode (no live actions yet; receipt-only). Each receipt contains the data the four artifacts call for. The next implementation milestone is lifting that data into four explicitly named files matching the schemas above, but the discipline is already legible in every receipt the loop emits.
A real example from the first day of running: the box’s Python urllib library could not establish HTTPS to api.telegram.org because the modern Let’s Encrypt root certificate was not in Python’s default Windows trust bundle. The Telegram sensor returned SSL CERTIFICATE_VERIFY_FAILED on iteration one. The Sensor Roll Call recorded the error honestly. The Gap Map named the missing context (no Telegram updates this iteration). The policy stage saw the gap, classified the iteration as escalate, and proposed a structured operator message naming the broken dependency. The discipline of “name what is broken even when it is the loop’s own dependency” worked exactly as designed. The Telegram sensor went from CERTIFICATE_VERIFY_FAILED to status: ok after a one-line fix; the discipline caught the failure before any downstream reasoning depended on the absent data.
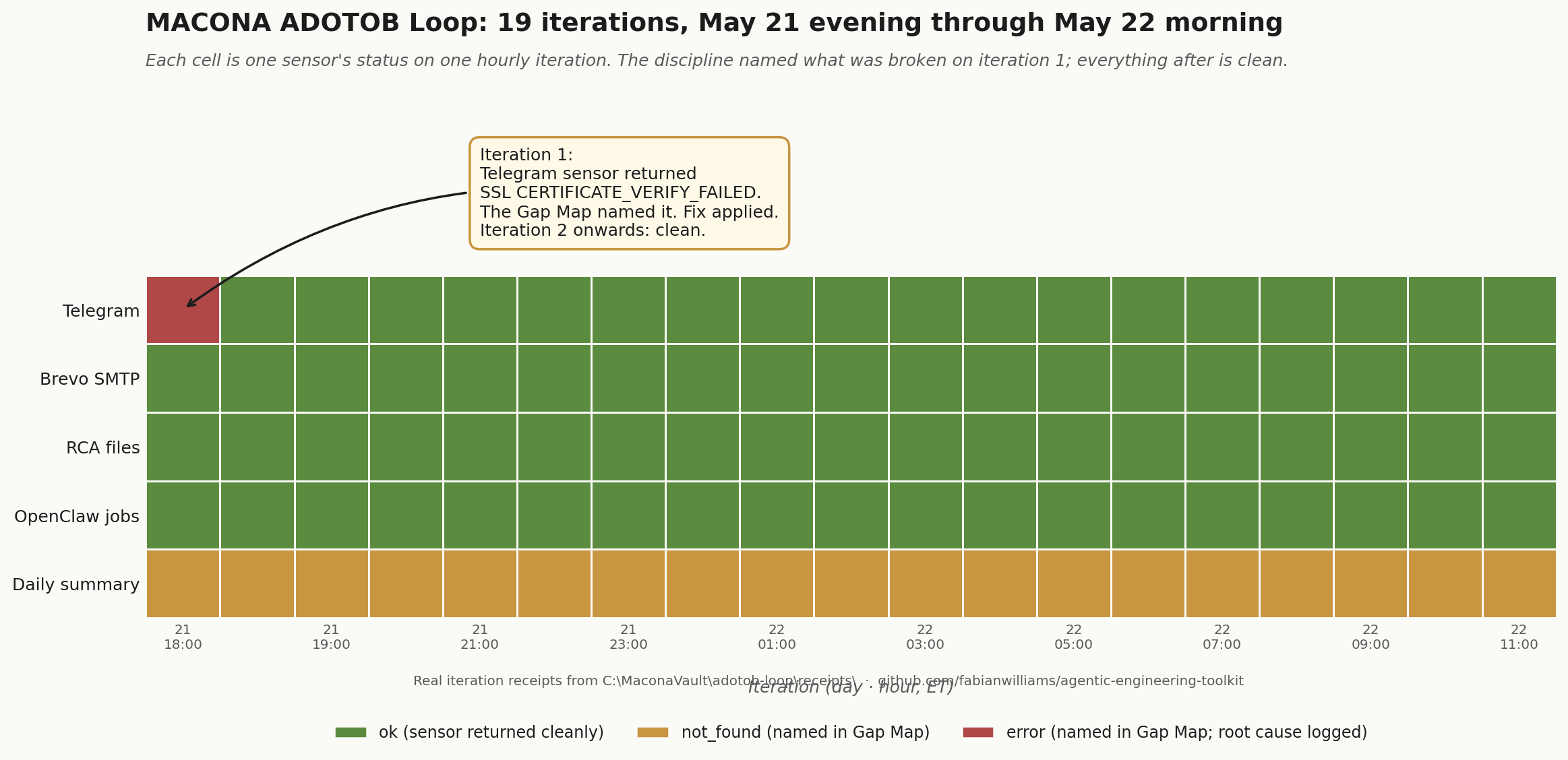
The chart above is real data from the receipts directory on the box. Every cell is one sensor’s status on one hourly iteration. The red cell is iteration one’s broken Telegram. The amber row across the bottom is daily_summary returning not_found every hour, faithfully named in the Gap Map until the operator points the configuration at the right directory. Nothing here is illustrative; every cell comes from a real sensor.json written by the loop.
This is the difference between an agent that runs and an agent that runs honestly. The four artifacts are how you make the difference visible.
How it pairs with Announce Intent Before Action
Announce Intent Before Action is the matched discipline on the ACTION side: every agent tool description must enumerate every server-side effect the call will produce, in seven categories (data, identity, communication, issuance, public, money, trigger). Sense Before Act is the matched discipline on the OBSERVATION side: every iteration must produce the four artifacts before the policy stage runs.
The two together form the per-iteration arc:
| Stage of the arc | Discipline | Question it answers |
|---|---|---|
| Observe | Sense Before Act | “What does the agent know right now, and where are the gaps?” |
| Announce | Announce Intent Before Action | “What is the agent about to do on my behalf?” |
| Act | (tool fires; the runtime executes) | “What happened?” |
| Verify | Audit-trail receipt | “Did what was supposed to happen actually happen?” |
Both bookend disciplines are required. A system with only the observation half lets agents act blindly even though they reason well; a system with only the action-announcement half lets agents act on invented context even though they announce their actions cleanly. The pair is what makes agent safety legible.
Why prompts cannot solve this
If you have ever told a language model “do not hallucinate” or “be careful with sources” or “double-check before acting,” you have already discovered that those instructions do not prevent the failure mode this discipline addresses. There is no separate “truth check pass” inside the model that the instruction hooks into. Asking a model to be careful is like asking autocomplete not to autocomplete.
The structural fix is to make the room before the model is asked to do anything in it. You build the inventory first. You surface the conflicts first. You name the gaps first. You catch the duplicates first. THEN the policy stage runs against artifacts that exist, not against absences the policy has to invent around.
The principle is borrowed from scientific instrumentation, not from prompt engineering. A telescope does not improve by being told to find better stars; it improves by being calibrated against known reference points before observation begins. An agent does not improve by being told to be careful; it improves by being required to emit four artifacts that establish what it observed before it decides. The discipline names the agent as an instrument and the iteration as a scientific observation. Both metaphors are older than computing.
Asking a model to be careful is asking autocomplete not to autocomplete. The fix is structural, not rhetorical.
What the discipline gives a buyer evaluating an agent platform
If you are evaluating an agent vendor and you want to know whether they have paid down this slice of supervision debt, ask them three questions:
For any given iteration, can you produce the list of every sensor that fired, with status and timing? If the answer is “we have logs in Datadog,” they have monitoring. They do not have a Sensor Roll Call. The difference matters when a sensor silently errors and downstream reasoning depends on its absence.
When two of your sensors disagree about the same fact, how does the agent decide? If the answer involves “the model figures it out from context,” they do not have a Conflict Receipt. They have a hidden judgment call.
What does the agent record when a piece of expected state is missing? If the answer is “we handle that case in the prompt,” they do not have a Gap Map. They have a tax on every renewal cycle when a missing field cascades into a wrong decision.
A vendor that produces all four artifacts on every iteration is operating to a discipline. A vendor that produces none has supervision debt at the observation layer, regardless of what their dashboard looks like.
Where to find the discipline
The Sense Before Act discipline lives in the Agent Reliability Kit at agents/sense-before-act. Apache 2.0. Use the names, use the schemas, port them to your own runtime.
Sister disciplines in the same kit:
- Announce Intent Before Action: the matched action-side discipline.
- Self-Improving Fleet Loop: the 5-stage loop that Sense Before Act lives at stage 1 of.
- ADOTOB Loop: the reference runtime that produces the four artifacts every iteration.
- Where the Kit Fits: the architectural map showing how the Kit pairs with whichever runtime, identity, data, and write-access stack a partner has already chosen.
The full Agent Reliability Kit is at github.com/fabianwilliams/agentic-engineering-toolkit. Apache 2.0. Star or watch if you want updates; the repo grows when something is worth adding, not on a schedule.
Contributions
What this post has offered:
- A name for a failure mode that prompts cannot fix: an agent that decides without first emitting the four artifacts that would have caught the structural error.
- Four required artifacts (Sensor Roll Call, Conflict Receipt, Gap Map, Cross-Source Dedup) with stable schemas and named failure questions each prevents.
- A worked example from a production fleet (the Telegram SSL incident on the MACONA Surface) showing the discipline catching a real failure on day one.
- Three diagnostic questions a buyer can ask any agent vendor to test for this slice of supervision debt.
- A matched pair (Sense Before Act and Announce Intent Before Action) that close the per-iteration arc together.
- A pointer to the running code, the running fleet, and the running receipts. The discipline is not aspirational; it is shipping.
The scientific method has been a working discipline for a long time. The application to agent runtimes is what is new. The rest is just notation.
Cheers, Fabian Williams
If you are building agents for clients and the procurement-shaped questions in this post sound familiar, I would value a 20-min back-and-forth on where the patterns hold and where they break. The licensed (non-sanitized) Kit covers the worked examples this post sketches.
- Blog: fabswill.com
- Twitter/X: @fabianwilliams
- MCP storefront: mcp.adotob.com
- Agent Reliability Kit (OSS): agentic-engineering-toolkit
- Partner licensing: estore.adotob.com/partners
Agent Reliability Kit™ is a trademark of Adotob Solutions.