The AI Agent Fleet Works. The Trust Funnel Does Not.
A small autonomous AI agent fleet I run as a volunteer for a 501(c)(3) nonprofit. Week 19 shipped 17 reliability PRs, 2 awareness-day blog posts, and 37 cold introductions — and earned zero human clicks, zero donations. This is the corrections panel I wrote on my own retro before anyone else could.
TL;DR
I volunteer with MACONA, a 501©(3) nonprofit that ships food, medicine, feminine hygiene products, donated computers, and clothing to communities and schools in West Africa. For a few few monthis now I have run a small autonomous AI agent fleet for the organization: five named agents, cron-driven, running through OpenClaw on a simple Windows box.
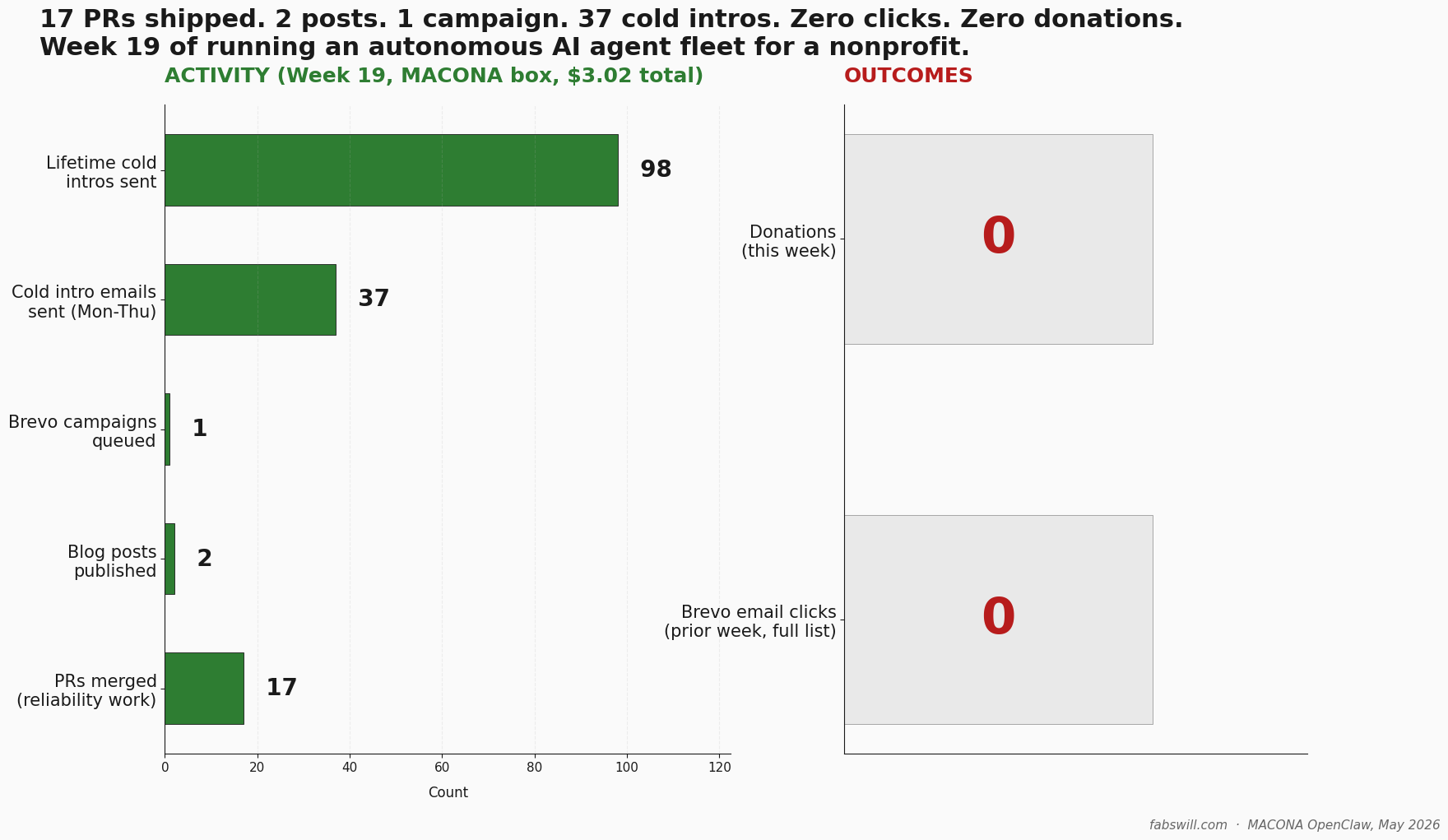
Week 19 (I track progress via week numbers for me and my Agents) looked like a win on every internal activity metric: 17 reliability PRs merged, 2 awareness-day blog posts published, 1 Brevo campaign queued, and 37 cold introduction emails sent.
The outcome metrics were brutal: zero human clicks and zero donations.
This post is about that gap — and about the corrections panel I wrote on top of my own retrospective before anyone else could.
The fleet works. The trust funnel does not yet.
What the receipts actually say
Week 19 (May 4 to May 8, 2026) was the most operationally productive week the fleet has had since I stood it up. The shipping list:
- 17 reliability PRs merged into the private MACONA OpenClaw repo. Most were fixes for bugs the fleet itself had surfaced through its own autonomous monitors. PR titles ranged from
feat(cron-wrappers): kill the natural-language-action fabrication patterntofix(meta-extract): regex now handles apostrophes inside quoted content— a real bug that had truncated a blog post’s social-card title to just “MACONA.” - 2 awareness-day blog posts published end-to-end. Both went brief → writer-agent draft → QA-agent review → publish → newsletter-campaign creation, with the agents doing every step until the manual-promote gate.
- 1 Brevo campaign queued for one of the posts — test-sent to four internal reviewers, sitting in draft to 59 active newsletter subscribers, awaiting my manual promote click.
- 37 cold introduction emails sent Monday through Thursday from the CEO’s mailbox via Microsoft Graph delegate access. Net-new recipients, deduped against the sent log. Lifetime cold intros across the box: 98. The daily breakdown: 12, 10, 11, 4, 0.
- 12 list-hygiene contact mutations across four Brevo lists — 11 bouncing contacts deleted, an alias-duplicate resolved, one friendly cross-match recovered from the blacklist.
That last day — zero intros — is important and I will come back to it.

The hard line
The same dashboards that confirm the activity numbers tell me what came back from the prior week’s newsletter sends to the same 59 subscribers: zero human clicks. Not a low click rate. Not a disappointing one. Zero. The donations counter for Week 19 is also zero — that’s Stripe donations through the public donate page, plus matched Benevity gifts through the corporate portal. Neither increased.
The newsletter list is small but real, and the engagement signal for the prior week was marginal. That number does not appear in most agent-fleet writeups. It should. The honest one-line I wrote at the bottom of my own retrospective the evening it shipped was this:
We shipped a lot of repair work — most PRs were fixing bugs we had shipped or had latent — built useful infrastructure, and produced activity but no outcomes. Zero human clicks, zero donations, and the outreach queue ran dry Friday. That is not failure on a week-19 horizon; it is a sign the agent fleet is generating motion without conversion, and the retro should have weighted that more honestly.
So we redrafted the Retro and I wrote (with the aid of the agent) that paragraph as a corrections panel because the first draft of the retro skewed positive. The pattern of writing the corrections panel is the thing I want to talk about…but first, the discipline that makes the receipts trustworthy in the first place.
The fleet, in as little detail as needed
5 named agents plus a cron daemon, running through OpenClaw on a small Windows box. Telegram is the primary channel; I get a morning brief, a midday inbox sweep, an end-of-day digest, and ad-hoc alerts when anything needs my attention.

The agents have personas! Mimi (orchestrator), Eshe (writer), Kofi (QA), Ama (campaigns), Sam (inbox triage + cold outreach). The fleet runs on a mix of gpt-4o and gpt-4o-mini. The cron daemon fires the agents at specific times across the day; the agents fire wrappers; the wrappers do the actual work.
A note on cost. The $3.02 number cited in this post is LLM API spend only, verified against the OpenClaw Gateway dashboard. It excludes hardware (a one-time Windows laptop), Microsoft 365, Brevo, Hunter.io enrichment credits, domain and hosting, and my volunteer time. For context, my home side-project box (Ada, on a Mac mini, a family-coordination agent, not a competing operational fleet) ran $13.48 over the same window. The gap is session shape: short cron tasks that complete-and-end beat long exploratory sessions on total spend. Cache hit rate is a diagnostic, not a scoreboard.
Why the numbers are trustworthy
The reason I can publish a zero-clicks line is that I trust my agents to report what they actually did. That trust did not exist eight days ago. It exists now because of one architectural rule.
PR #27, merged Monday 2026-05-04: feat(cron-wrappers): kill the natural-language-action fabrication pattern.
Before PR #27, several cron jobs had prompts that said things like “Compose a Brevo-ready campaign email for the latest published post.” The agent, gpt-4o, with no deterministic tool constraining it — would respond with a paragraph saying it had composed the email. No file got written. No campaign got created. The Telegram report said task complete. Disk state said otherwise.
I had been catching these by accident for weeks. Once I named the pattern, I removed it. Every cron action now follows one strict rule: the action step must be backed by an exec wrapper that calls deterministic Python, the wrapper emits structured summary_lines and a verified flag, and the agent’s job is to relay those lines and stop. No natural-language verbs in the prompt. No compose, send, process. The agent is a courier for the wrapper’s report, not a doer of the work.
In plain English: the agent is no longer allowed to claim it did work just because it wrote a convincing paragraph. A script has to do the work first, produce evidence, and then the agent is only allowed to report that evidence.
That single architectural rule is the most reliability-positive thing I have done so far. The agents have not invented an action since. (More precisely…they have not invented an action in the categories I was watching. I will come back to that.)
The other discipline that compounds with the wrapper rule is closed-loop bug protocol: every bug, no matter how small, lands as incident → PR → RCA → monitor. Friday’s cleanest example: a recovery script I had written by hand on Wednesday introduced a missing closing quote on an inline image tag. The agent’s broken-image monitor caught it autonomously at 1pm Friday. Telegram surfaced it. I shipped a one-line fix in twenty minutes. The monitor that caught it had been added to the fleet weeks earlier — not because I anticipated this specific bug, but because the broken-image class was worth monitoring once. The fleet caught the bug I introduced. That is the loop working.
Why the framing still lied — the corrections panel
The original Week 19 retrospective drafted on Friday evening read like most internal retros do: complete content + campaigns + outreach pipeline; first end-to-end autonomous awareness-day post; anti-fabrication scaffolding holding; cost discipline. It was not wrong on the numbers — every dollar and PR count was correct. It was wrong on the framing.
I sent the draft to myself, walked away for an hour, came back, and read it as if a stranger had written it about my work. I noticed 4 overclaims and 5 missing facts, appended a corrections panel to the top, and shipped the document with both readings preserved.
Here is what the corrections panel looked like — paraphrased, since the source retro contains internal details:
4 overclaims I caught
“Complete content + campaigns + outreach pipeline.” Outreach was running on draining inventory, not a healthy pipeline. A latent quota-check bug had been silently failing the enrichment side for an unknown duration. The pipeline only appeared working because the existing inventory hadn’t drained yet.
“First end-to-end autonomous awareness-day post.” The post required three manual interventions before it was clean: a hand-written recovery script for an apostrophe-bailing regex, a closing-quote fix on an inline image tag, and the manual promote-to-newsletter click that’s still pending.
“Anti-fabrication scaffolding holding.” Friday alone surfaced two new misreport patterns the existing scaffolding didn’t catch — both the same shape as the PR #27 fabrication class, just expressed differently. Old categories caught; new ones leaked through.
Implicit “good week” framing throughout. I had not yet seen the zero-engagement signal that arrived in the 3pm brief. The activity-versus-outcomes gap deserved more weight than the original retro gave it.
5 things I missed: the zero-clicks number; the actual day-by-day cold-intro send count; the latent nature of the enrichment bug; the broader month-over-month trajectory; one actionable follow-up due that day.
What the retro got right: the cost numbers, the PR list, the bug RCA table, the decisions made and why.
The honest one-line: we produced activity but no outcomes. That is not failure on a week-19 horizon; it is a sign the fleet is generating motion without conversion, and the retro should have weighted that more honestly.
That panel is not a rewrite of the original retro. It is an additive audit sitting above it. Reading the original retro followed by the corrections panel gives the most accurate picture; reading either alone misleads.
I have come to think of the corrections panel as the most important section of any retrospective I write. It is the thing that makes the rest of the document trustable. When a reader sees you flagging your own overclaims with the same specificity you used to make the original claims, they trust the original claims more. The integrity is in the audit, not in the absence of mistakes.
Eric Ries made this same point on Lenny’s Podcast over the weekend, talking about why some companies stay mission-aligned for a century and others corrode within a decade. His bridge analogy: when a bridge collapses, gravity is a useless explanation, because gravity is always there. The bridges that stay up have stainless-steel structural integrity in places that look like overengineering until the wind comes. Writing the corrections panel before anyone else can write one for you is the small-org equivalent of that overengineering. It is harder than just shipping the rosy retro. It is also the only path to a retro anyone should believe.
The new fabrications that leaked through
For completeness, here is what those two new misreport patterns looked like:
The intro-drip cron labeled a clean empty-queue no-op as
task failed. The wrapper correctly returnedeligible: 0. The agent’s summary paragraph said “Today’s intro batch failed to execute.” The wrapper was honest; the agent’s interpretation was not.The content-pipeline cron labeled a clean SKIP as
execution skips. Same shape. The wrapper said “no awareness day matched today, skipping.” The agent reported “the content pipeline experienced skips.”
Both are the same class of error as PR #27 fixed — the agent narrating around the structured truth instead of relaying it. Both leaked through because PR #27 closed the invent an action that never happened door, not the re-interpret a successful skip as a failure door. The next prompt-tightening PR will name and kill the new class. That is the loop.
The third leak was uglier: same Friday, the 3pm Benevity weekly brief reported “0 enriched, 72 remaining” while the 10am research run from the same day reported “46 of 72 portals enriched.” Two reports, same day, same metric, contradictory numbers. The root cause was a silent field-name drift — one script returning the Hunter API quota under one key name, another script reading it under another. The enricher had been silently failing for an unknown number of days. The existing 41-row contact CSV drained Monday through Thursday at about ten intros per day. Friday it hit zero, and the bug surfaced.
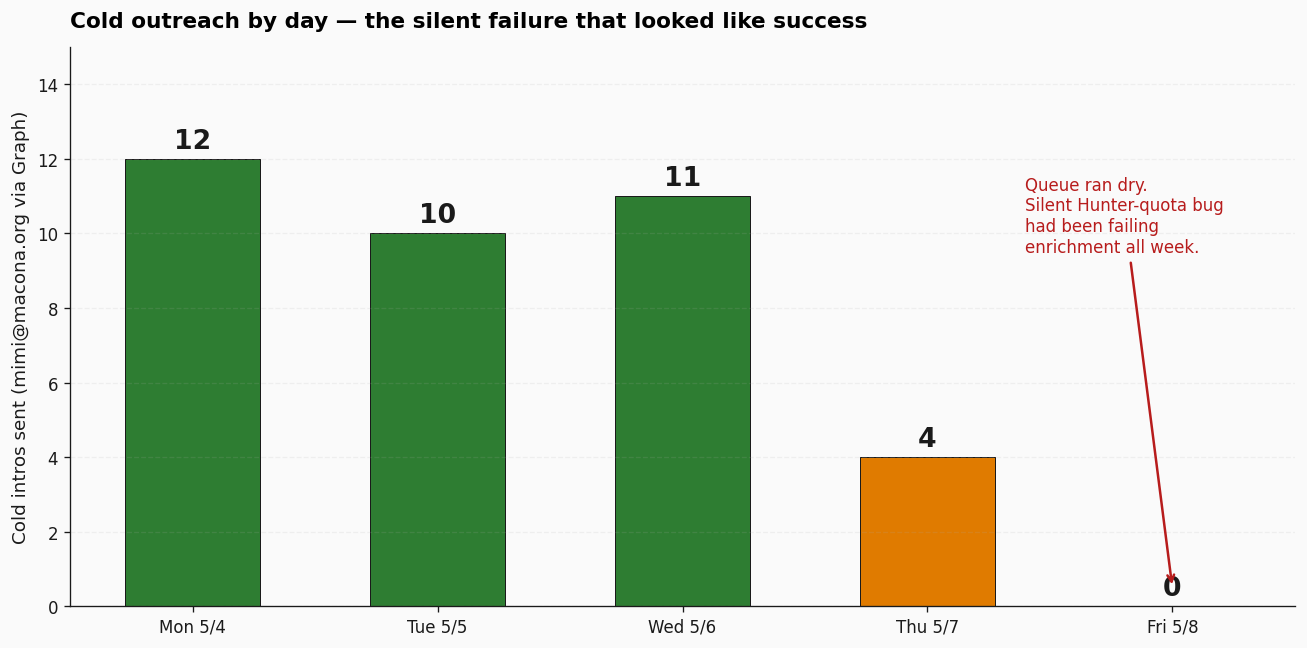
The lesson worth carrying: monotonic decay in a queue without monotonic refill is invisible until the queue hits zero. The system appeared healthy because the existing inventory drained at the expected rate. The fix is a one-line alert: when enrichment delta equals zero for N consecutive days, surface a warning.
Anti-fabrication baked into the briefs themselves
The other place the fleet defends against fabrication is in the work orders themselves. The writer agent drafts blog posts from a brief produced by the awareness-day cron. The brief is a structured markdown file — frontmatter, required elements, editorial guardrails. This morning’s Mother’s Day brief reads, in part:
No fabricated people. Names, ages, locations, quotes must come from the vault or be left generic (“a volunteer in Kumasi”, “a donor from the MVP Summit cohort”). See
feedback_no_fabricated_personal_details.mdif uncertain.No fabricated metrics. Numbers (“we delivered 1,000 kits”) must be traceable to vault records. If unsure, omit.
That paragraph lives inside the prompt the writer sees. The fabrication guardrails are not bolted on at QA time — they are written into the work order itself. The QA agent, downstream, then verifies the rubric: minimum five images, exact path format for inline images, donation link must use the canonical short-link format, EIN must appear in the HTML, word count between 800 and 1500.
When you build a fleet to ship at this cost, this is the trade-off: the constraints have to be in the prompt and in the wrapper and in the QA gate, not in the operator’s head. Anything that lives only in the operator’s head gets lost the first time the operator is offline.
Seven lessons I am carrying into Week 20
Wrap every cron action in an exec script that emits structured
summary_linesand averifiedflag. Natural-language do X steps in agent prompts fabricate. Every time. The wrapper-pattern is the single biggest reliability improvement I have made.Closed-loop = PR plus RCA plus monitor, every time. A bug fix without a monitor is a bug invitation. The monitor that catches a recurrence is the receipt that the fix held.
Inspect raw artifacts before inferring. I spent four PRs fixing an inbox classifier that couldn’t detect a particular bounce format. Should have been one PR. I would have nailed it in one if I had dumped the raw email body via the upstream API before writing the regex. Do not iterate in fog.
Monotonic decay in a queue without monotonic refill is invisible. The quota bug silently failed enrichment for an unknown duration. The existing inventory drained at the expected rate, masking the failure. Add an alert: if a refill metric is flat for N days, surface it.
Soft warnings beat hard rejections for content-quality fabrication risk. Hard-blocking on probabilistic signals stalls the pipeline. Soft warnings let humans intervene when needed without freezing the autonomous loop.
Cache hit rate is a session-shape signal, not a cost signal. Tight cron-style sessions that complete-and-end beat long iterative chats on total spend. Lower cache rate, lower bill.
Write the corrections panel before anyone else can write one for you. This is the structural integrity the rest of the retro hangs on. Same-day. Additive, not destructive. Read together with the original.
Why this matters beyond my setup
Most agent-fleet retrospectives that exist publicly are marketing artifacts — a vendor explaining why their product worked, or a founder pitching the next round. Honest weekly retros from operators of small autonomous fleets are rare. The reasons are obvious. They show what does not convert, not just what shipped. They show the bugs the operator introduced, not just the bugs the system caught. They show the activity-versus-outcomes gap, which is where most fleets actually live.
I am publishing this one because the discipline of writing it and writing the corrections panel on top of it — is, I now believe, the single most underrated component of running an agent fleet at all. The cost numbers and the reliability counts are real. They are also unimpressive without the audit panel that says what they do not mean. With the audit panel, they become useful, for me, deciding what to change next week, and for anyone reading this trying to figure out whether the autonomous-agent-fleet thing is worth building.
Closing
The fleet can ship. It can monitor. It can catch some of its own failure modes. It can run for $3.02 a week of LLM spend.
What it has not yet proven is that motion becomes trust, or that trust becomes donations.
The fleet works. The trust funnel does not yet.
That is Week 20’s work.
Cheers, Fabian Williams
I build autonomous AI agent fleets and the eval scaffolding to keep them honest. If you run an agent fleet for a small org and you write weekly retros — especially the ones where the receipts do not match the headline — I would like to compare notes.
- Blog: fabswill.com
- LinkedIn: fabiangwilliams
- Twitter/X: @fabianwilliams
- GitHub (Agentic Engineering Toolkit): agentic-engineering-toolkit