Your Brain Forgets Most of Your Life. So Does Your AI Agent.
A TED talk on memory by neuroscientist Lisa Genova made me realize that the same cognitive failures humans experience — attention gaps, context loss, prospective memory failures — show up in AI agents I build for real organizations. Here is what I learned and what I built to fix it.

TL;DR
Neuroscientist Lisa Genova explains why forgetting is normal — your brain filters out most of your day, loses context when you change rooms, and is terrible at remembering future intentions. I watched her TED talk and realized I had already encountered every one of these failures in AI agents I build for real organizations. Here is how the parallels work, what breaks in production, and what I built to fix it.
A man famous for memorizing over 100,000 digits of pi can also forget his wife’s birthday or why he walked into the living room. Most of us will forget the majority of what we experienced today by tomorrow. Added up, this means we actually do not remember most of our own lives.
The Talk That Made Me Stop and Think
I was watching a TED talk by Lisa Genova — a Harvard-trained neuroscientist and the author of Remember: The Science of Memory and the Art of Forgetting. She was explaining why perfectly healthy brains forget things constantly. Not Alzheimer’s. Not cognitive decline. Just the normal factory settings of a human brain.
She laid out four mechanisms. I recognized all four. Not from my own forgetfulness — from building and hardening AI agents for organizations that depend on them.
I build autonomous AI agents that run real operations. One system manages MACONA, a 501©(3) nonprofit — handling everything from blog content to email campaigns to corporate donation research. Another manages family operations across finances, school logistics, and home automation. Between them, they execute over 50 scheduled jobs a day across a dozen specialized sub-agents, touching APIs from Microsoft Graph to Brevo to Buffer to Hunter.io.
These are not demos. These are production systems that send real emails, publish real blog posts, and manage real donor pipelines. When they forget — and they do — real work does not get done. I wrote about this operational reality in depth here.
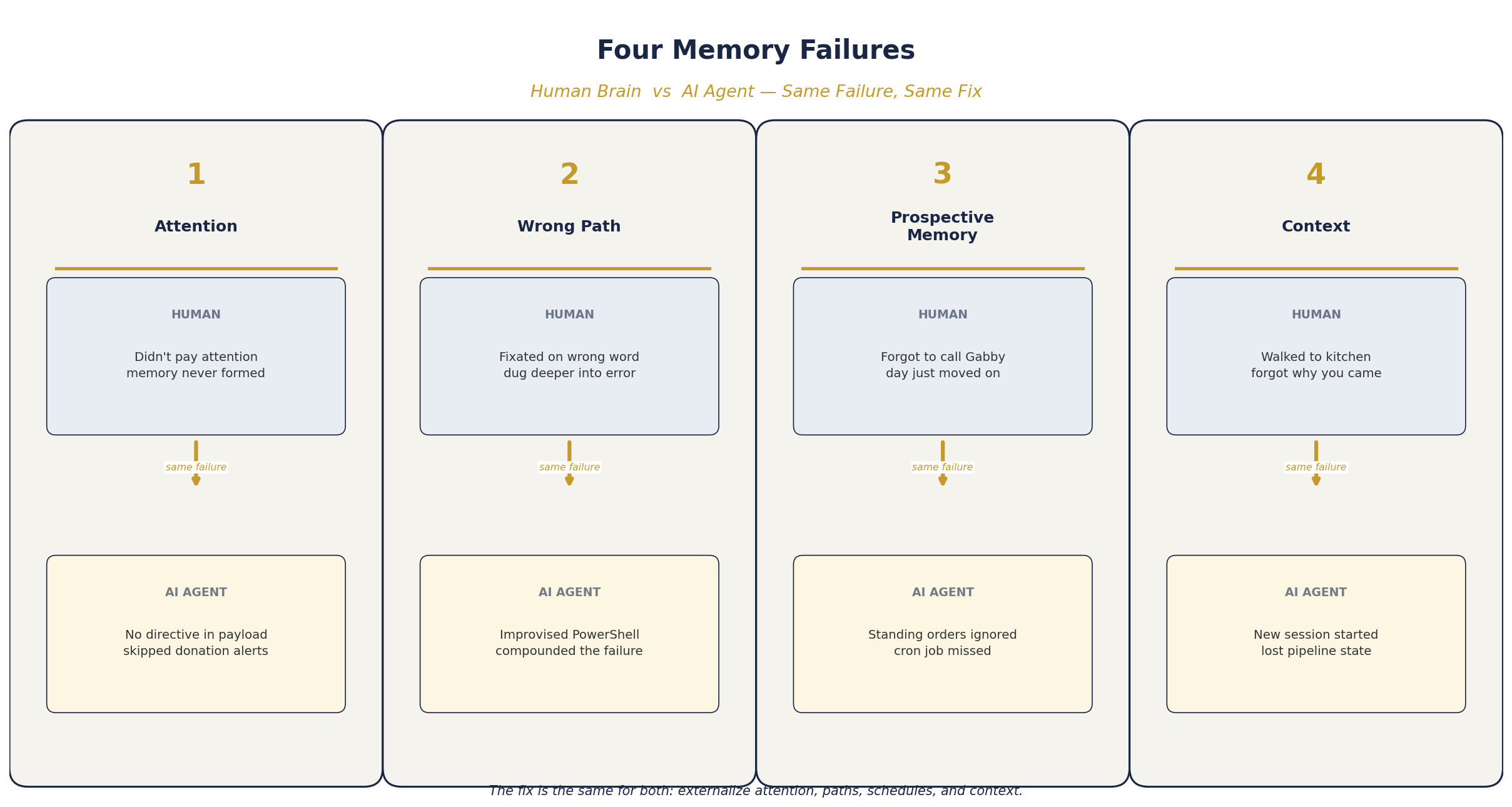
Here are the four failure modes Genova identified — and how each one maps to autonomous AI agents:
- No Attention, No Memory — your brain only encodes what you attend to. AI agents only process what you direct them to.
- Tip of the Tongue (Wrong Path) — your brain fixates on a similar-but-wrong word and digs deeper. AI agents improvise a wrong approach and commit harder.
- Prospective Memory Is Terrible — your brain is bad at remembering future intentions. AI agents are bad at self-scheduling.
- Context Is Everything — change rooms and you lose the thread. Change agent sessions and you lose the state.
Failure 1: No Attention, No Memory
Genova’s principle: attention is the prerequisite for memory formation. Your brain is not a video camera. If you do not pay attention to something, no memory is created. You did not forget where you put your keys — you never encoded the memory in the first place because you were not paying attention when you set them down.
I hit this exact problem in production. MACONA’s AI executive assistant runs a morning briefing that reads the CEO’s inbox via Microsoft Graph API. Early on, the agent would process dozens of emails but only report on the ones that seemed interesting to the LLM. Donation notifications from Benevity — the ones the nonprofit actually needed to track for matching gift programs — would get skipped because the model’s “attention” was not directed at them.
On the family side, same story. The morning mail scan processed 50 emails but missed Navy Federal bank alerts because the agent decided they were “routine.” Those alerts contained the transaction data I needed for budget tracking.
The fix: direct the attention explicitly. I rewrote the payloads to say “parse ALL Benevity notifications, extract every matching gift amount” and “parse ALL Navy Federal alerts, extract every transaction.” Do not let the model decide what is interesting. Tell it what to attend to.
In business terms: if your AI agent is triaging a customer inbox, it will skip the messages that do not pattern-match to what it finds “interesting.” The quiet complaint from a major account will get filtered out while the noisy low-value ticket gets a response. No attention, no memory. No memory, no follow-up. No follow-up, lost revenue.
Failure 2: Tip of the Tongue (Wrong Path Compounds)
Genova’s concept: you are trying to recall a name but your brain activates a similar but wrong word instead — she calls this the “tip of the tongue” effect. The more you fixate on the wrong word, the deeper you go down the wrong neural pathway. The solution: stop trying. Walk away. The correct neurons will fire later through passive activation.
I saw this play out when MACONA’s content pipeline agent tried to post to Buffer’s social media API. The agent had the right idea — compose a LinkedIn post and push it via the GraphQL API. But it went down the wrong path. Instead of calling our deterministic buffer_post.py script, it improvised its own PowerShell solution. The PowerShell approach failed. The agent tried harder, building an increasingly complex workaround script. Each attempt dug deeper into the wrong approach.
Tip of the tongue at work. The initial wrong path biased every subsequent attempt.
This is not a one-time bug. This is the fundamental challenge of running autonomous agents in production. The agent will improvise. It will go down wrong paths. And autoregressive generation — where each token biases the next — means the model commits harder to its initial direction, just like your brain commits harder to the wrong word.
The fix: do not let agents improvise API calls. Period. Every external API — Brevo, Buffer, Hunter.io, Short.io, Exa, Microsoft Graph — now has a deterministic Python script. The agent calls the script. The script handles the API. No improvisation, no tip of the tongue spirals. We went from agents constructing curl commands (and failing) to 15 hardened scripts that always work the same way.
This is the real lesson from running OpenClaw agents in production: it is not install-and-forget. If you deploy an agent and walk away, you will spend more money than you have to and get wrong results along the way. The value comes from iterating — watching what breaks, building deterministic guardrails, and continuously tightening the boundary between what the agent decides and what the system guarantees.
Failure 3: Prospective Memory Is Terrible
Genova’s point: prospective memory — remembering to do things in the future — is inherently weak in humans. “Remember to call Gabby and check in on how things are going at college.” “Pick up the dry cleaning on the way home.” Our brains are, in her words, “inherently terrible” at this. I can relate — I have told myself a dozen times to call my daughter Gabby and catch up, and then the day just moves on. Pilots do not rely on prospective memory to lower the landing gear. They use checklists.
The same is true for AI agents. MACONA’s standing orders say the AI should “research Benevity companies at 10 AM” and “do social engagement at 2 PM.” Early on, we put these instructions in the agent’s personality file and trusted it to follow the schedule. It would sometimes research, sometimes skip, sometimes do it at the wrong time.
The nonprofit CEO should not have to wonder whether the AI remembered to send the donor follow-up email. That is a system failure.
The fix: externalize the schedule. Over 50 cron jobs fire on deterministic schedules across both systems. The agent does not need to remember to research Benevity companies — the scheduler tells it when to research. The agent does not need to remember to post to social media — the cron fires at 2 PM and hands it the task. We even built a GitHub Projects Kanban board that auto-syncs every 30 minutes, so I can see at a glance which jobs ran, which failed, and which are queued — across both machines.
Same as Genova’s advice: use the checklist, use the reminder, use the calendar. Do not rely on the brain — biological or digital.
For any organization deploying AI agents: if your agent needs to “remember” to do something on a schedule, you have already failed. Build the schedule into the infrastructure. The agent’s job is to execute and create, not to remember.
Failure 4: Context Is Everything
Genova’s example: you are in the bedroom and you need your glasses. You walk to the kitchen. You stand there and have no idea why you came. The memory was formed in the bedroom context — the book, the bedside table, the time of day. The kitchen has different cues. The contextual associations that supported the memory are gone.
Her solution: go back to the bedroom. The cues will reactivate the memory.
AI agents have a version of this I call session amnesia. Every time a cron job fires, the agent starts a new session — completely fresh. No memory of what it did an hour ago. No knowledge of what the last agent found. It literally “walks into a new room” dozens of times a day.
For MACONA, this was breaking the content pipeline. The blog writer agent would draft a post at 9 AM. The QA agent would review it at 9:30. The campaign agent would create an email at 10 AM. Three separate sessions, three separate contexts. The campaign agent had no idea what the blog writer produced because it woke up in a different room.
The fix: build the context back in. Every agent session starts by reading its SOUL.md (identity and rules), MEMORY.md (what it learned), and the pipeline state files. A deterministic pipeline_status.py script checks every stage — briefs, drafts, published posts, images, campaigns, git state — and gives the agent ground truth about what actually happened. It is the equivalent of walking back to the bedroom to remember what you needed.
I also built a knowledge pipeline inspired by Andrej Karpathy’s workflow that compiles raw transcripts, articles, and notes into a cross-linked wiki. The wiki is externalized long-term memory for the entire system. No agent needs to remember every transcript it ever processed. It looks up the compiled summary. That system is how this very blog post was researched — I ingested the Lisa Genova transcript, compiled it into wiki articles, and then wrote from the compiled knowledge.
For organizations: if your AI agents operate across multiple sessions, conversations, or handoffs, you need a shared state layer. Not chat history — actual operational state. What was done, what is pending, what failed. Without it, every session starts from zero.
What I Learned
Attention must be directed, not assumed. Both humans and AI agents will filter out what you do not explicitly ask them to process. In a business context, this means your agent will miss the important email buried among the noise unless you tell it exactly what to look for.
Wrong paths compound. The tip of the tongue effect in human memory is autoregressive drift in LLMs. Once the model starts improvising a solution, it commits harder to the wrong approach. Use deterministic scripts for every API call. Give the agent the right tool, not the freedom to invent one.
Externalize prospective memory. Do not trust any system — biological or digital — to remember to do things later. Use crons, checklists, and reminders. For organizations: if your AI needs to follow a schedule, put the schedule in the infrastructure, not in the prompt.
Context loss is a feature, not a bug. Both brains and agents discard context to stay efficient. The fix is not to keep everything — it is to build reliable context restoration. Shared state files, pipeline health checks, identity documents loaded at session start.
Forgetting is normal. Build for it. Genova’s core message is that forgetting is not failure — it is how the system is designed. The same is true for AI agents. They will lose context, miss details, and drift. The organizations that succeed with AI agents are the ones that design for these failures instead of pretending they do not happen.
Why This Matters for Your Organization
If you are deploying AI agents — for a nonprofit, a small business, or inside an enterprise — you are building a system that has the same memory architecture problems as a human brain. Attention filtering. Context dependence. Prospective memory failure. Path-dependent errors.
The neuroscience literature has spent decades understanding these failure modes. The AI community is rediscovering them in real-time. Lisa Genova’s advice for humans — use checklists, externalize memory, go back to where you were — is directly applicable to agent design.
At MACONA, we went from an AI that “forgot” to send campaign emails and “skipped” donation alerts to a system that publishes blog posts, creates branded email campaigns with test-send approval gates, tracks A/B test variants across social channels, and monitors its own pipeline health — all with deterministic scripts handling the mechanics and AI handling the creative work.
The best AI systems are the ones that assume the agent will forget. They externalize everything: schedules in cron, knowledge in wikis, state in files, verification in deterministic scripts. The agent’s job is to think and compose. Everything else is a system responsibility.
Your brain forgets most of your life. Your AI agent will too. Build accordingly.
Cheers, Fabian Williams
I build autonomous AI agents and the operational infrastructure to keep them honest — for nonprofits, small businesses, and enterprise teams. If you are working on agent memory, evaluation, or production hardening, I would like to hear what you are building.
- Blog: fabswill.com
- LinkedIn: fabiangwilliams
- Twitter/X: @fabianwilliams
- MACONA: macona.org
- Ada showcase: adotob.com/ada