Vibe Coding with AI – Best Practices for Every Project
Learn how to use evaluation-first development, GitHub Copilot, Claude, and local LLMs to build faster, smarter AI-powered apps.

🚀 Introduction
This guide captures a modern, evaluation-first approach to building AI-powered projects using tools like GitHub Copilot, Claude, ChatGPT, and local LLMs like LLaMA and DeepSeek.
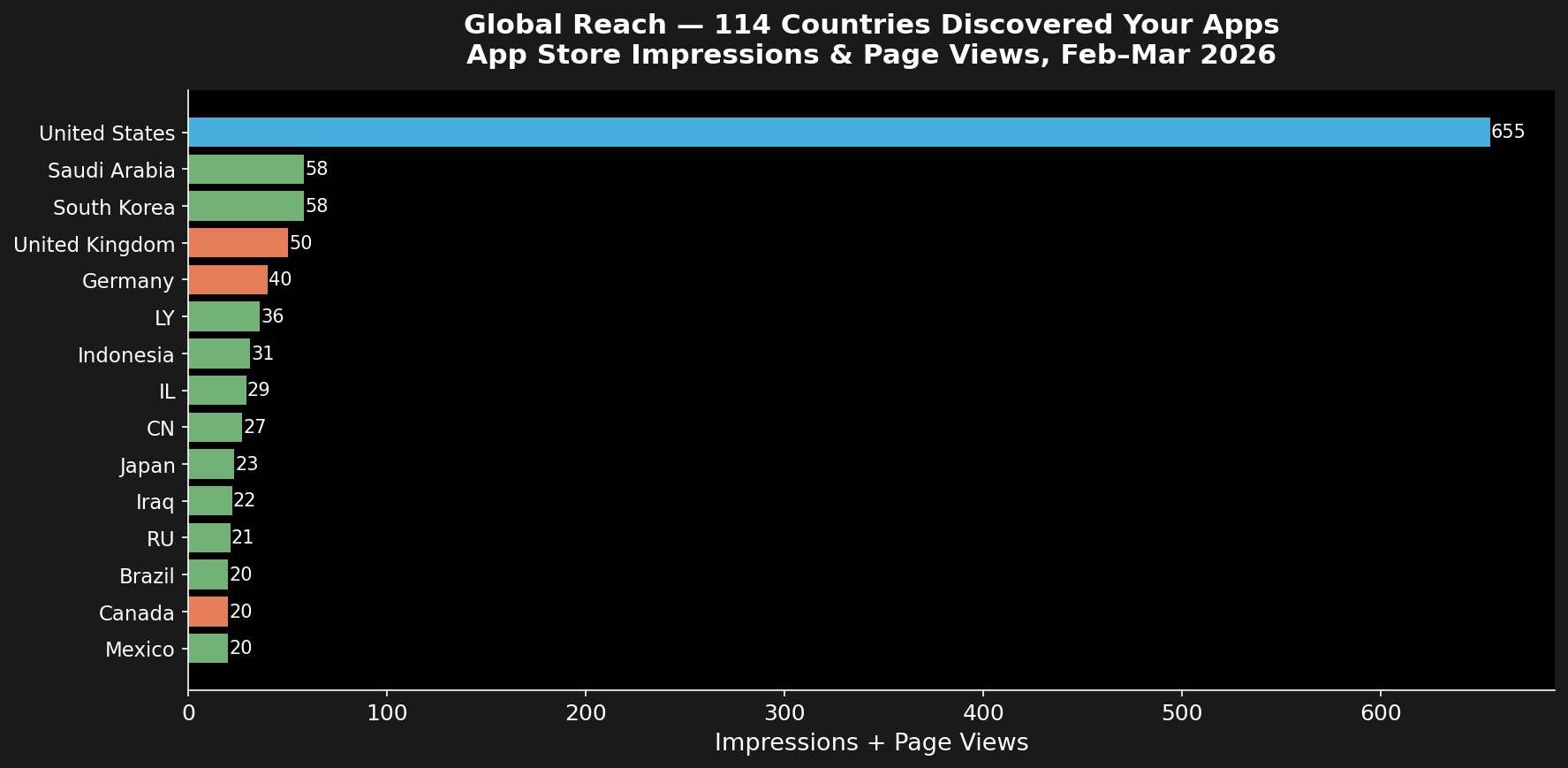
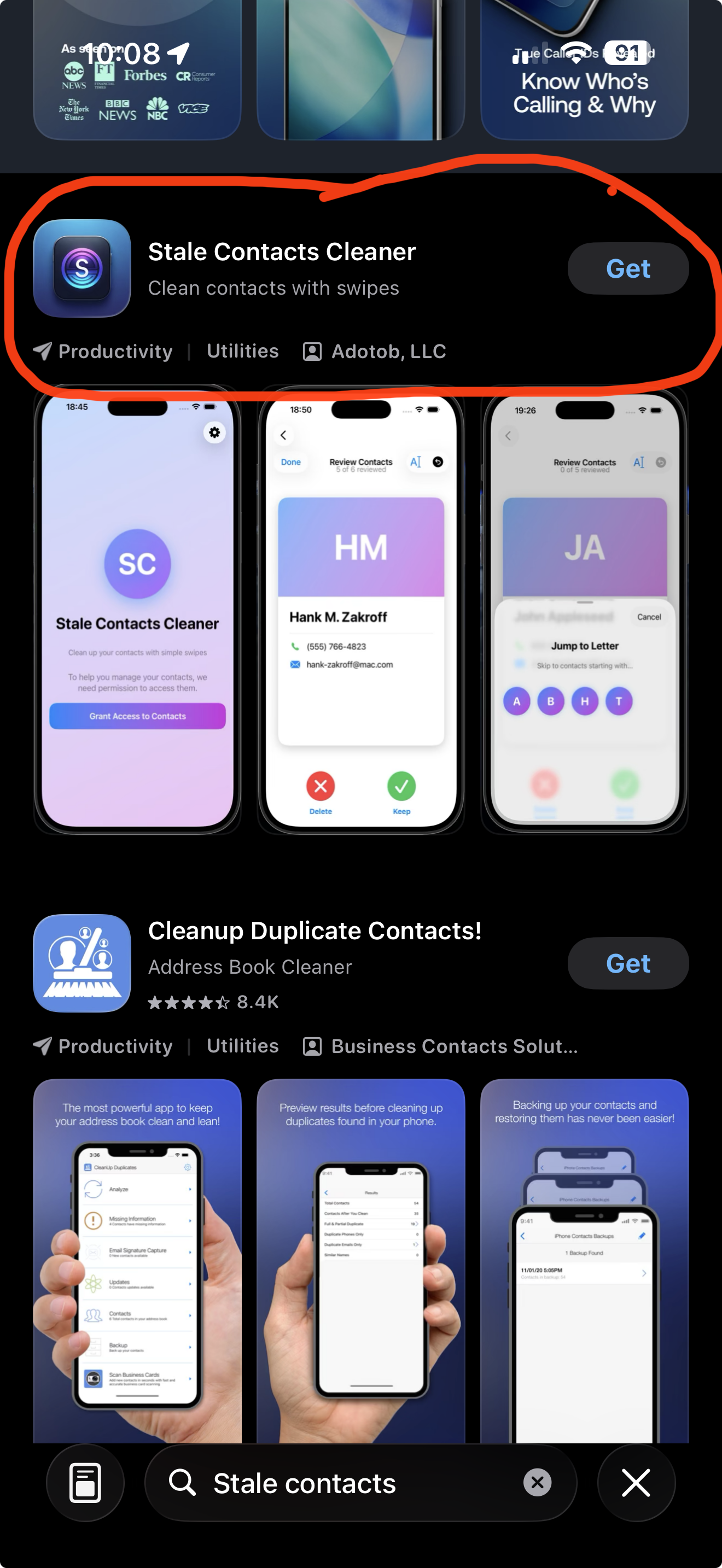
We’ll use AsyncPR — a real-world mobile app project I built and shipped — as the public example. Check out a YouTube short video I did here on the App https://go.fabswill.com/asyncpr-shortintro and feel free to test it out! This guide reflects how I work today: VS Code as my IDE, Copilot for code assist, and running private models on my MacBook when needed for security or speed.

Grab the app in the App Store for iOS here https://apps.apple.com/app/id6744700840
If you’re serious about modern software building, you’ll love this framework.
🛠️ Purpose and Setting Expectations
This is not a theory doc written after the fact — it’s a living guide captured while actively working.
Key details:
- IDE: Visual Studio Code (VS Code)
- Primary AI Tools: GitHub Copilot, ChatGPT, Claude Desktop
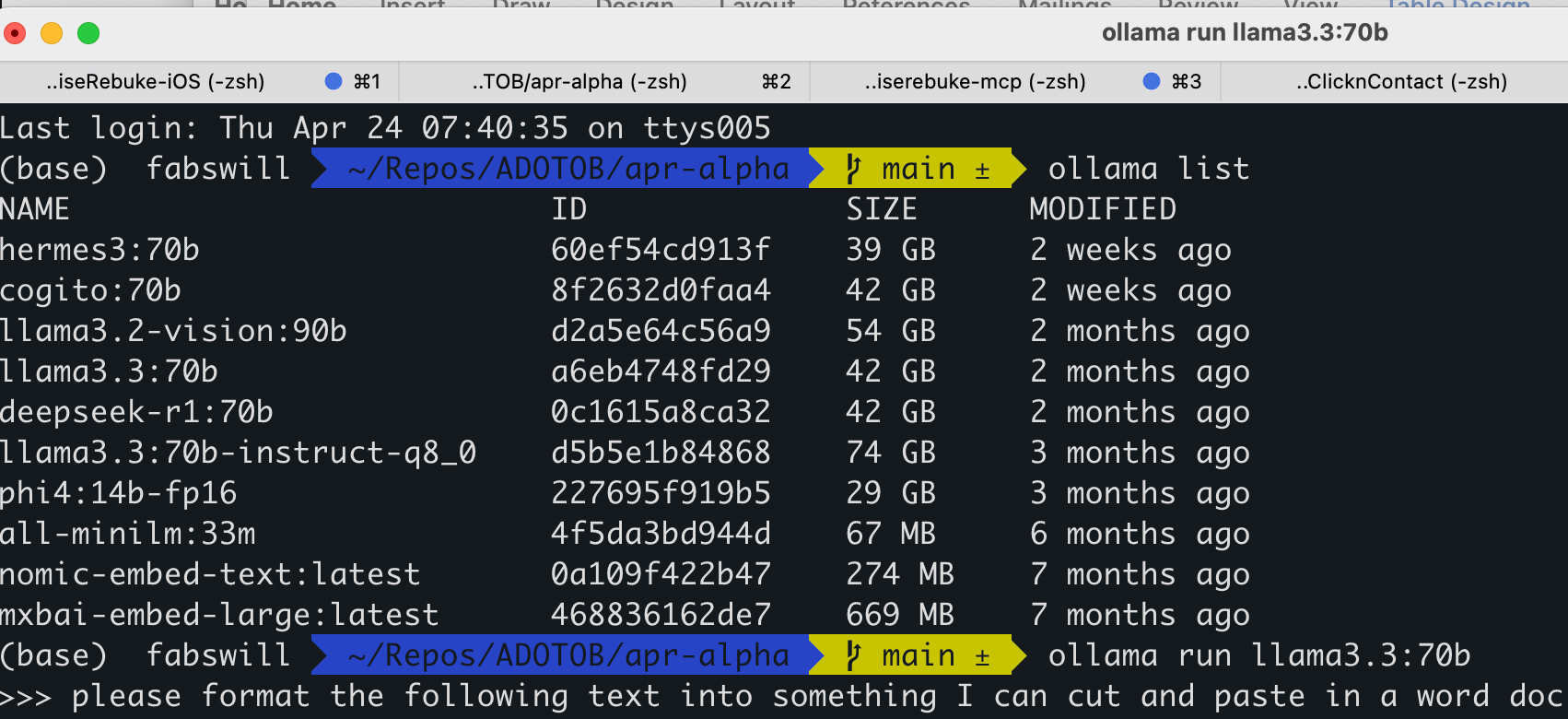
- Local Models: LLaMA 3.3:70B, DeepSeek 70B (via Ollama)
AsyncPR is featured because my private projects at work can’t be shared publicly — but the principles, practices, and rigor are identical.
🧠 Mindset Shift: From Testing to Evaluations (Evals)
| Old Way | New Way |
|---|---|
| Test after building | Eval before building |
| Check if code “works” | Check if code “works the right way” |
| Hope AI outputs are fine | Define “good” first, then build |
✅ Plan → Eval → Build → Test
🧪 Start with Evaluations (Evals), Not Just Tests
Before writing any production code, define Evals: - What does a good output look like? - What would success/failure look like? - How can a real user journey be simulated?
📋 Examples from AsyncPR:
- Receipt image → extracted business name? ✅
- Business name → valid business email? ✅
- Customer narrative → clean, structured feedback JSON? ✅
Think of Evals like mini contracts between you and your AI tools.
📂 Save these in /evals/ folder for every project.
📋 Project Planning Before Coding
This is the step that saves you the most pain:
Work with the LLM to write a PLAN.md:
- Must-Have Features
- Nice-to-Haves
- Out-of-Scope (for now)
The AI cannot read your mind — writing this plan forces clarity upfront.
🛠️ Tool Setup and AI Strategy
Today, my stack looks like:
- VS Code + GitHub Copilot for core coding
- Windsurf or Cursor for AI copartnering coding
- Claude Desktop/Code for architectural planning and debugging
- Custom MCP Servers for API documentation lookup and internal data sources
- Local Ollama Models (LLaMA, DeepSeek) for private projects
My main IDE of choice is VS Code with GitHub Copilot and given a choice I am coding in .NET C#, when I face less of a choice its still VS Code but its in Python or TypeScript
Ive also started to dabble in Cursor and Windsurf, which is a clone of VS Code, I do like Windsurf native and dare I say easier approach to built in MCP support in the tooling configuration over Claude and VS Code.
I think I am just fanboying with using Claude Desktop because MCP is from Anthropic and Claude is too which also makes the Docs easy to follow when I was getting up to speed. I use this to test my MCP Servers as well.
🎯 Mindset: Treat AI tools like a team of interns — powerful but needing precise guidance.
🌀 Iterative, Section-by-Section Development
Build one section at a time:
✅ Implement small pieces
✅ Validate against Evals
✅ Only then commit to Git
Never let bad AI outputs pile up. Reset early and often.
🗂️ Version Control is Sacred
- Work from clean Git branches.
git reset --hardif AI drifts too far off course.- Use GitHub Actions to validate key rules.
Trust me: you’ll thank yourself later.
📊 High-Level Testing Always
Once Evals pass, simulate real-world behavior:
- I often use Insomnia or a basic Blazor SPA to hit real endpoints.
- Validate the entire user journey, not just isolated function outputs.
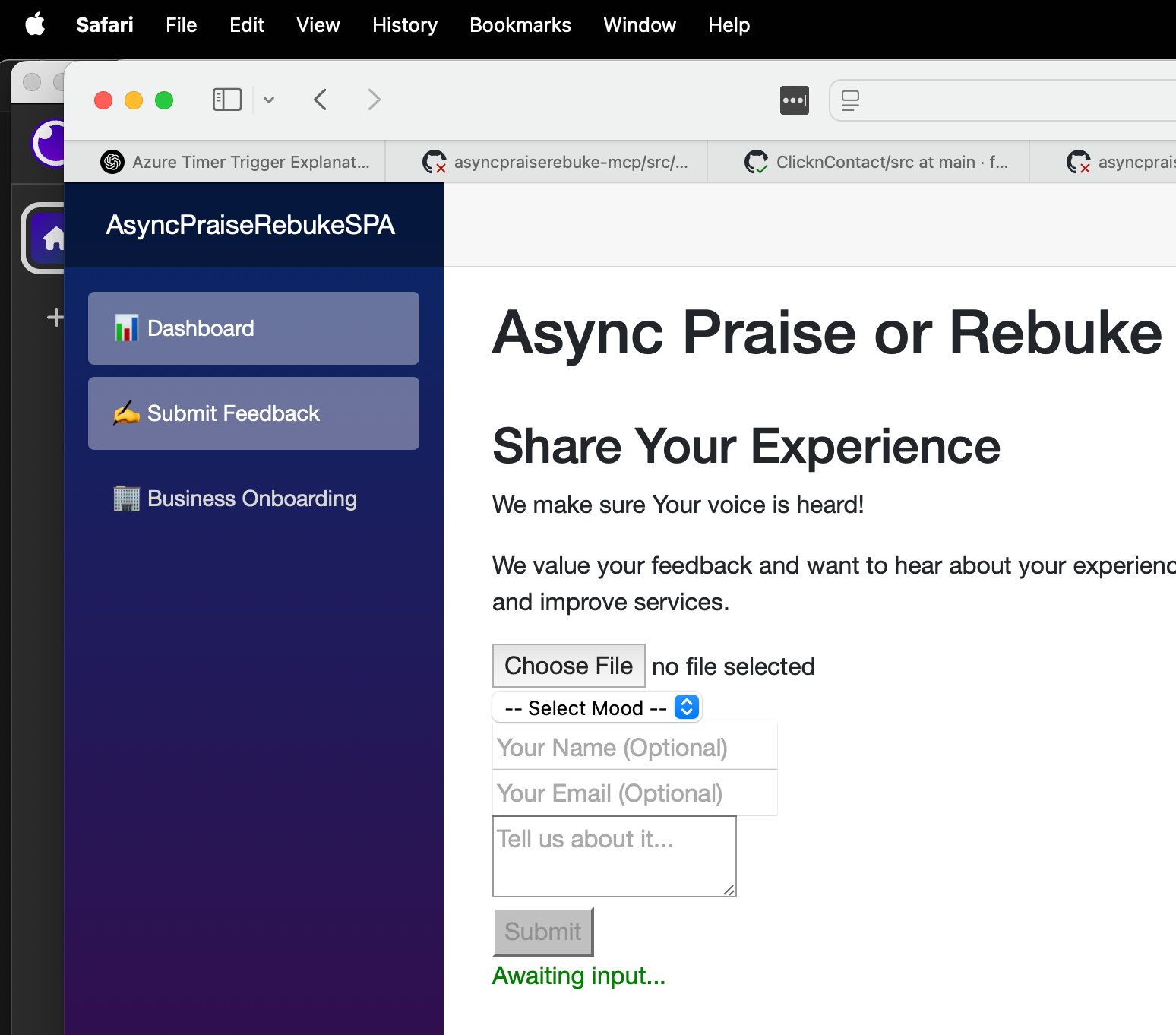
📚 Deep Documentation and Accessibility
Docs aren’t just for humans anymore — they’re for AIs too.
- Save API specs, database schemas, business rules under
/docs/ - Build MCP Servers that live-ingest updated docs
- Even scrape and save static Markdown from sites if needed for local models
🛠️ Refactor Relentlessly
When the tests pass, refactor: - Break apart monolith files - Create small, focused modules - Ask your LLMs to suggest refactors too
Small files = happier humans and happier AIs.
🧠 Choose the Right Model for the Job
Some models are better at: - Planning: Claude and DeepSeek - Autocompleting: GitHub Copilot - Domain Reasoning: Your own MCP Servers
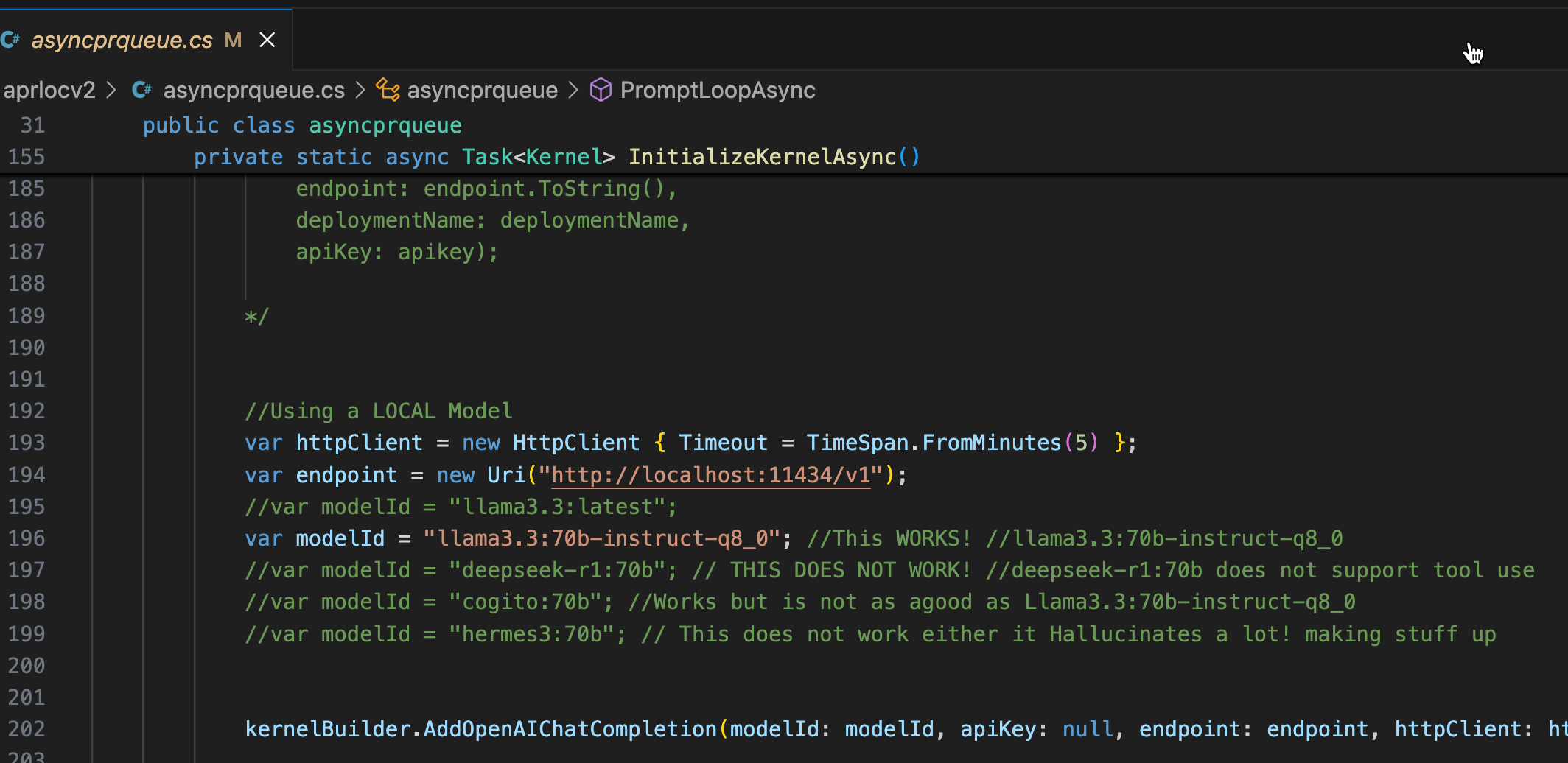
Experiment, experiment, experiment.
🔄 Keep Iterating
Every few weeks: - Try new models on old logic. - Update your Evals. - Share learnings with yourself (and your future teammates).
Vibe coding is about building smarter and faster — both.
📂 Example Project Structure
/my-project-name
│
├── .gitignore
├── README.md
├── PLAN.md # Detailed project plan with must-have, nice-to-have, out-of-scope
├── LLM_INSTRUCTIONS.md # Special instructions to AI agents
│
├── /src # Application code
│ ├── /backend
│ ├── /frontend
│ └── /shared
│
├── /tests # High-level user journey tests (Post-Eval validation)
│
├── /evals # Manual or automated Evals
│ ├── image-processing-eval.md
│ ├── business-name-detection-eval.md
│ ├── feedback-generation-eval.md
│ └── README.md # Explains your Evals philosophy
│
├── /docs # API docs, specs, architecture references
│
├── /scripts # Utility scripts (e.g., image resizing, data migration)
│
├── /mcp-servers # (Optional) Local MCP server configurations
│
└── LICENSE
💬 Final Thoughts
AI-assisted development demands a new way of thinking.
Evaluation-first frameworks, thoughtful planning, and tight Git discipline make the difference between chaos and clarity.
AsyncPR is just the beginning — this approach scales to any project, any team, any goal.
🎯 What’s one Eval you’ll try first? Comment or message me — let’s level up together!
Chat with me
| Engage with me | Click |
|---|---|
| BlueSky | @fabianwilliams |
| Fabian G. Williams |